[검색엔진최적화] SEO에서 Search Engine(검색엔진)이란?

웹사이트, 블로그를 상위에 노출시키려면 공부하게되는 검색엔진최적화[SEO(Search Engine Optimiztipn)].
크게 보면 내가 쓴 정보를 각 검색엔진에 노출시키는 방법으로 말할 수 있지만,
정확히 어떤 원리에서 그렇게 되는지, 무슨 기준으로 상위노출이 되는지 헷갈리기만 합니다.
일반적으로 SEO를 위해서 써치콘솔과 같은 웹마스터 도구, 사이트맵, Robots.txt를 설정하게 됩니다.
사실 위 과정만 거쳐도 어느정도 효과는 볼 수 있습니다.
웹마스터 도구에 등록하는 이유는 검색 엔진이 크롤링하기 수월하도록
우리 사이트를 등록하는 과정이기 때문이니다.
이러한 과정 후에 사용자들이 무엇으로 검색하고 들어오고 어떤 콘텐츠를 많이 찾았는 지,
GA(Google Analytics)로 확인하는 것 역시 메우 중요합니다.
검색엔진들은 최신의 자료를 좋아하기 때문에 단기적으로는 효과가 일 수 있으나,
장기적으로 SERP(검색결과페이지) 노출을 유지하려면 어떤 것들을 조정해야하는지가 중요합니다.
물론, 본 문서에서는 Ranking factor(순위 요소)에 대한 내용보단 검색엔진에 대한 개념과 원리를 먼저 알아보고자합니다.
목차
검색엔진이란?

검색엔진(Search Engine)은 인터넷 상에서 사용자들이 특정 키워드나 질의를 입력하면 그에 맞는 검색 결과를 제공하는 컴퓨터 기반의 프로그램 또는 웹 서비스를 말합니다. 주요한 검색 엔진으로는 Google, Naver, Daum, Nate, Bing, Yahoo 등이 있으며, 이러한 검색 엔진은 수많은 웹페이지를 색인화하고, 사용자의 검색 요청에 따라 가장 관련성 높은 결과를 반환하는 역할을 합니다.
검색 엔진은 크롤링, 인덱싱, 랭킹 등의 단계를 거쳐 검색 결과를 생성합니다. 먼저, 검색 엔진은 웹사이트를 크롤러(웹 크롤러 또는 스파이더)를 통해 수집하고, 이후 수집한 웹페이지를 인덱싱하여 데이터베이스에 저장합니다. 이렇게 저장된 데이터베이스를 기반으로 검색 엔진은 사용자의 검색 질의와 관련성이 높은 웹페이지를 검색 결과로 제공합니다.
복잡한 알고리즘을 사용하여 웹페이지의 관련성, 신뢰성, 사용자 경험 등을 평가합니다. 이 알고리즘은 수많은 요소를 고려하여 검색 결과의 순위를 결정합니다. 일반적으로 검색 엔진은 사용자들에게 가장 유용하고 관련성이 높은 정보를 제공하기 위해 웹페이지의 콘텐츠, 키워드 사용, 외부 링크, 사용자 신뢰도 등을 평가합니다.
검색 엔진은 인터넷 사용자들에게 다양한 정보를 제공하며, 비즈니스에게도 중요한 역할을 합니다. 웹사이트나 온라인 비즈니스의 가시성을 높이기 위해서는 검색 엔진에서 상위에 노출되는 것이 중요합니다. 따라서 검색 엔진 최적화인 SEO가 중요한 전략이 되고 있습니다. SEO는 웹사이트가 검색 엔진에서 높은 순위를 차지하도록 최적화하는 작업을 포함합니다.
검색 엔진이 검색결과를 순서를 정하는 방법
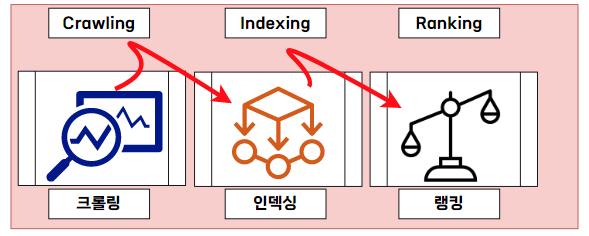
크롤링 - 검색엔진이 내 글(콘텐츠)을 가져가는 과정
크롤링은 온라인 상의 데이터를 자유로이 움직이면서(동적으로) 데이터를 수집하는 것을 말합니다. 이제는 크롤링이 많이 대중화되었지만, 일반인들에겐 여전히 어려운 개념일 수 있습니다. 크롤링은 검색엔진에서만 쓰는 기술이 아닌 빅데이터에서 주로 쓰이는 기술입니다.
모든 검색엔진은 검색결과를 제공하기 위해 다양한 사이트, 도메인에서 정보들을 가지고 와야합니다. 정보들을 가지고 와야 다시 정렬하여 검색엔진결과페이지(SERP)에 뿌려줄 수 있습니다.
기억하셔야할 점은 크롤링은 검색엔진이 우리 사이트, 블로그에 업로드한 정보를 수집해가는 것을 말하며, 이 수집 과정에 문제가 생기면 내가 올린 글이 노출이 안된다는 것입니다. 이를 방지 하기 위해 Robots.txt와 Sitemap을 설정하는 것이며 각 검색엔진의 웹마스터 도구에 등록하는 것입니다.
다음은 크롤링 수행 방식입니다.
- 시작 URL 설정: 크롤러는 크롤링을 시작할 웹 페이지의 URL을 설정합니다. 이는 크롤링의 출발점이 되는 페이지입니다.
- 웹 페이지 다운로드: 크롤러는 시작 URL에 접속하여 해당 웹 페이지의 HTML 코드를 다운로드합니다.
- HTML 파싱: 다운로드한 HTML 코드를 파싱하여 웹 페이지의 구조와 내용을 이해합니다. 이를 위해 보통 HTML 파서(HTML Parser)를 사용합니다.
- 링크 추출: 파싱한 HTML 코드에서 다른 링크를 추출합니다. 이 링크는 크롤러가 다음에 방문할 웹 페이지의 URL이 됩니다. 일반적으로 <a> 태그의 href 속성 값을 확인하여 링크를 추출합니다.
- 크롤링 대기열 유지: 추출한 링크들을 크롤링 대기열에 유지합니다. 대기열은 크롤러가 방문할 웹 페이지의 순서를 관리하는 역할을 합니다.
- 다음 웹 페이지 크롤링: 대기열에서 다음으로 크롤링할 웹 페이지의 URL을 가져와 위의 단계를 반복합니다. 이를 재귀적으로 반복하면서 웹 페이지를 순차적으로 크롤링합니다.
인덱싱- 검색엔진이 내 글(콘텐츠)을 분류하는 과정
인덱싱(Indexing)이란 색인을 말합니다. 크롤링해서 수집한 정보를 특정 카테고리나 주제로 구분하는 것입니다. 정보들을 구분하기 위해, HTML 내의 구조를 살펴봅니다. 그래서 SEO에서 시멘틱이 중요한 것입니다. 색인을 마친 정보들을 구조화된 형태로 저장하면 검색결과역시 빠르게 제공할 수 있습니다. 인덱싱 과정에서 수집한 웹페이지의 텍스트를 추출합니다. 추출한 텍스트에서 키워드를 식별하고, 역색인화하여 인덱스 데이터 구조를 구성합니다. 이후 압축 및 저장을 통해 인덱스를 관리하고, 새로운 웹 페이지의 추가나 변경 시에 업데이트를 수행합니다. 검색 엔진의 인덱싱은 다양한 기술과 알고리즘을 활용하여 대용량의 웹 페이지를 효율적으로 처리하여 사용자가 원하는 정보에 빠르게 접근할 수 있도록 합니다.
인덱시 과정
- 크롤링: 검색 엔진은 크롤러를 사용하여 웹 페이지를 수집합니다. 크롤러는 URL을 추출하고 해당 URL에 접속하여 웹 페이지의 HTML 코드를 다운로드합니다.
- 문서 파싱: 다운로드한 HTML 코드를 파싱하여 웹 페이지의 구조를 이해합니다. 이 과정에서 HTML 태그, 문단, 제목 등의 정보를 추출합니다.
- 텍스트 추출: 웹 페이지에서 텍스트 내용을 추출합니다. 이를 위해 HTML 태그를 제거하고, 텍스트 데이터를 정제하고 가공합니다. 예를 들어, 스크립트 코드, 스타일 시트, 주석 등을 제거하고 텍스트를 정규화하여 적절한 형태로 추출합니다.
- 키워드 추출: 추출한 텍스트에서 중요한 키워드를 식별합니다. 이를 위해 자연어 처리 기술을 사용하여 문장 분리, 형태소 분석, 어휘적 특징 추출 등의 과정을 거칩니다.
- 역색인화: 추출한 키워드와 관련된 정보를 인덱스 데이터 구조로 구성합니다. 일반적으로 역색인(인버티드 인덱스)이 사용되며, 키워드를 키로 하고 해당 키워드가 나타나는 문서의 목록을 값으로 저장합니다.
- 압축 및 저장: 인덱스 데이터를 압축하여 저장 공간을 줄이고, 빠른 검색을 위해 메모리나 디스크에 저장합니다. 효율적인 데이터 구조와 알고리즘을 사용하여 인덱스를 관리합니다.
- 업데이트 관리: 새로운 웹 페이지가 추가되거나 기존의 웹 페이지가 변경되면, 이를 감지하고 인덱스를 업데이트합니다. 일반적으로 변경된 문서를 재크롤링하여 업데이트된 정보를 추출하고 인덱스를 갱신합니다.
랭킹- 검색엔진이 내 글(콘텐츠)을 노출하고 순서를 정하는 과정
랭킹은 노출 순위를 나타내며 SEO를 하는 궁극적인 목적입니다. 우리가 작성한 블로그글, 자사의 웹사이트, 제품이나 브랜드가 있는 페이지를 상위에 노출 시키고 싶기 때문에 앞의 과정에서 분류된 내 정보의 순위(Ranking)가 높아지게 하고 싶은 것입니다.
대부분의 사람들이 말하는 상위노출의 조건은 이미 랭킹이 높은 글들을 보며 적립되어 온 것입니다.
키워드가 중요하다는 것은 너무 뻔한 이야기입니다. 내 글에 내가 노출하고자하는 키워드가 없다면, 당연히 검색에 안나오는 것이기 떄문입니다.
키워드에 집중하면 반복 숫자로 인해, 웹사이트나 블로그가 저품질이 될 수 있습니다. 중요한 것은 정보성을 어떻게 표현해야하냐는 것입니다.
이 부분은 구글의 검색엔진에 대한 정보가 많습니다. 네이버나 다음, 네이트와 같은 국내 기업들의 검색엔진은 생각보다 복잡하지 않기 때문입니다. 네이버 블로그(글+그림 구조)가 네이버에 색인되는 방법의 정석입니다.
우선, 일반적을 검색엔진이 랭킹을 정하는 방법은 다음과 같습니다.
- 검색 쿼리 이해: 사용자가 입력한 검색 쿼리를 이해하기 위해 검색 엔진은 자연어 처리 기술을 사용하여 쿼리의 의도와 관련된 키워드, 구문, 문맥 등을 분석합니다.
- 검색어 관련성: 검색 쿼리와 웹 페이지의 내용, 제목, 메타 데이터 등의 요소를 비교하여 검색어와의 관련성을 평가합니다. 검색어가 페이지에서 중요한 위치에 나타나거나, 관련된 키워드와 함께 사용되는 경우 더 높은 관련성을 가집니다.
- 페이지 품질 평가: 검색 엔진은 웹 페이지의 품질을 평가합니다. 이는 페이지의 신뢰성, 신뢰할 수 있는 소스에서의 인용, 콘텐츠의 원본성 등을 고려합니다. 또한 사용자 경험, 페이지의 로딩 속도, 모바일 호환성 등과 같은 요소도 고려할 수 있습니다.
- 링크 관련성: 다른 웹 페이지로부터의 링크는 해당 페이지의 중요도를 나타내는 지표로 사용될 수 있습니다. 많은 외부 사이트로부터의 링크 또는 특정 주제와 관련된 신뢰할 수 있는 사이트로부터의 링크를 가지는 페이지는 상위 랭킹을 받을 수 있습니다.
- 사용자 신뢰도: 검색 엔진은 사용자들의 행동 데이터를 고려합니다. 사용자들이 특정 웹 페이지를 많이 방문하거나 긍정적인 피드백을 남긴 경우, 해당 페이지의 랭킹이 상승할 수 있습니다.
- 지리적 위치: 사용자의 지리적 위치와 검색 결과의 지리적 연관성을 고려할 수 있습니다. 지역적인 검색 쿼리의 경우, 해당 지역과 관련된 정보를 우선적으로 표시할 수 있습니다.
SEO - 순위에 영향을 미치는 요인 (공통 요인)
키워드
특정 키워드를 얼마나 많이 쓰냐가 아닙니다. 특정 키워드가 담긴 문서가 그 키워드를 얼만큼 설명할 수 있는지를 봅니다. 문장 내에 키워드가 포함되어 있고, 그 키워드와 연관된 다른 키워드들이 얼마나 포함되어 있는지 보는 것입니다.
한 20년 전쯤만해도 키워드 수 자체가 중요하여 특정 키워드를 흰색 글씨로 바꾸고 무조건 많이 넣으면 상위에 뜨곤 했습니다. 지금 그러면 바로 저품질입니다.
적당한 분량
이 부분은 적당한 정도가 중요합니다. 지나치게 길면 안되며, 너무 짧으면 당연히 정보성이 없는 것으로 판단하는 것 같습니다. 일부 웹페이지들을 보면 짧은 내용도 상위에 있는 경우가 있는데, 이 경우 그 사이트의 권위점수가 높거나 HTML 내에 구조나 전체 분량이 많아서 일 수 있습니다.
지금 이 글을 보시는 분들께 보이는 한글 텍스트외에 웹페이지 정보들은 더 많이 출력되고 있는데, 이는 F12를 눌러보시면 아실 수 있습니다. 이렇게 본문이 아닌 곳들에 대한 평가도 함께 이뤄지기 때문에 전체적인 HTML 구조가 중요합니다.
이미지, 동영상 등 추가 콘텐츠
블로그의 정석은 그림, 글, 그림 ,글의 반복입니다. 텍스트(text)이외에 그림(figure) 혹은 영상에 대한 점수가 추가로 있다는 것입니다. 물론, 타인의 것을 지속해서 가지고와 뿌려주는 것은 의미가 없을 수 있으며, 저작권상 문제가 될 수 있으므로 완벽하고 이쁜 이미지보단 직접 찍은 사진이나, 직접 제작한 사진이 더 의미가 있습니다.
시멘틱(Semantic)
내 글은 정보성이 넘치는데, 왜 노출이 안될까? 고민이시라면, 사람에게만 유용한 글을 작성한 것일 수 있습니다.
앞서 말한 크롤링은 크롤러라는 봇이 긁어가는 것을 말합니다. 그 다음 인덱싱 및 순위 조정도 웹 상의 봇이 결정합니다.
즉, 로봇의 입장에서 이 글이 중요한지를 판단하는 과정이 있다는 말입니다. 그에 맞게 html을 작성하는 것을 시멘틱 구조라고 합니다.
예를 들면 제목은 heading 태그에 내용은 p태그에 작성하는 것입니다. 사람은 글자 크기에 따라 제목과 본문을 구분할 수 있지만 로봇은 어려워합니다. 그래서 항목 하나하나를 봇이 파악하기 쉽게 작성해줘야합니다.
검색엔진 종류
검색 엔진들은 서로 지향하는 바가 달라, 시멘틱을 고려하더라도 서로 다른 순위로 노출됩니다. 이러한 이유는 각 기업에 중요하다고 판단하는 정보의 기준이 서로 다르기 때문입니다. 이 기준을 파악해야 해당 검색엔진에 상위에 노출 시킬 수 있지만, 당연히 기업에서는 공유하는 정보가 아닙니다. 정보가 아닌 정보인척하는 광고들 때문에 검색엔진들도 지속적으로 그 알고리즘을 수정하고 있습니다.
하나의 사이트를 모든 검색엔진에 맞추기는 어렵습니다. 하나의 검색엔진에 맞추고 동일 컨텐츠를 다른 방식으로 다른 사이트 혹은 SNS에 올리는 것이 효과적입니다. 일반적으로는 구글 SEO가 중심이 되고 네이버는 네이버 블로그를 이용하는 방식입니다.
각 검색엔진은 사용자들의 요구와 지역적 특성에 따라 다양한 서비스와 기능을 제공하고 있으며, 이를 고려하여 온라인 비즈니스나 웹사이트의 마케팅 전략을 수립할 때, 각 검색 엔진의 특징을 고려하는 것이 중요합니다. 예를 들어, 한국 시장을 대상으로 하는 경우 Naver와 Daum의 특화된 자체 블로그나 카페를 이용하는 것이 유리할 수 있습니다. 반면, Google은 특정 매체에 대한 편견이 없는 편이라 시멘틱하게만 맞춰주면 잘 노출되는 편입니다.
또한, 각 검색 엔진은 SEO(검색 엔진 최적화) 전략에도 영향을 미칩니다. 각 검색 엔진은 다른 알고리즘과 평가 요소를 사용하여 웹페이지의 순위를 결정합니다. 예를 들어, Google은 고품질의 콘텐츠와 외부 링크의 중요성을 강조하며, Naver는 특히 컨텐츠의 신뢰성과 사용자들의 평가를 고려합니다. 이에 따라 SEO 전략은 해당 검색 엔진의 특징과 요구에 맞추어 실행되어야 합니다.
1. Google

구글은 이미 검색엔진으로서 소비자에게 어떻게 도움이 되는 지 파악하고 있습니다.
그래서 내놓은 가설이 ZMOT((Moment of truth))입니다. 당신들의 브랜드가 우리 구글에 노출되면 분명 메출액에 도움이 됩니다.를 말하는 것이죠.
예 : 스마트폰 사려는 데 뭐가 좋지? → 스마트폰 추천 → 추천글 발견 → 갤럭시 S22 정보 확인 → 제품 구매 페이지 접속 → 구매
이러한 상업적인 목적에 앞서, 소비자들이 구글에 검색한 정보가 정말 가치 있는 정보인지가 중요하다는 것도 알고 있기 때문에, 네이버와 달리 상업적인 내용들은 표시된 유료광고로만 진행하고 나머지는 정보성이 높은 것을 우선 순위로 올려줍니다.

- 가장 인기 있는 검색 엔진 중 하나로, 세계적으로 널리 사용됩니다.
- 강력한 검색 알고리즘과 다양한 데이터 소스를 활용하여 관련성 높은 검색 결과를 제공합니다.
- 다양한 검색 기능과 서비스(이미지 검색, 동영상 검색, 지도 등)를 제공하여 사용자들의 다양한 요구를 충족시킵니다.
2. Naver
- 한국에서 가장 인기 있는 포털 사이트이자 검색 엔진입니다.
- 검색 결과 페이지(SERP)가 지나치게 광고판이어서 전세계 검색에진 중 정보성이 좀 떨이지는 편입니다.
- 한국어 검색에 특화되어 있으며, 한국어 사용자들에게 가장 관련성 높은 검색 결과를 제공합니다.
- 다양한 웹서비스(뉴스, 블로그, 카페, 쇼핑 등)와 연결되어 포털로서의 역할을 수행합니다.
3. Daum

- Naver와 유사한 기능을 가진 검색 엔진으로, 한국에서 많이 사용됩니다.
- kakao가 잘 이끌려고 노력하고 있지만, 매력적인 요소가 적은 것이 흠입니다.
- 하지만, 확연히 점유율이 낮습니다.
- 최근 카카오에서 독립적인 기업으로 구분한다는 이야기도 있습니다.
- 실시간 검색어 순위, 카페 등 다양한 정보를 제공하여 사용자들에게 실시간 이슈와 트렌드를 전달합니다.
4. Nate

- SK Communications에서 운영하는 포털 사이트로, 검색 엔진 기능도 포함되어 있습니다.
- 위 캡처본에서 검색창에 이미 광고가 있는게 눈에 띄네요.
- 광고에 집중하다보면 정보성을 잃는다는 것을 아직 모르는 듯합니다.
- 네이트는 판이 유명합니다.
- 다양한 정보와 서비스(뉴스, 금융, 엔터테인먼트 등)를 제공하여 다양한 사용자들의 요구를 충족시킵니다.
5. Bing
- Microsoft가 개발한 검색 엔진으로, Google에 비해 사용자 점유율은 낮지만 중요한 역할을 합니다.
- 최근 챗GPT의 기능을 탑재하면서 점유율을 올릴 것이라 기대되고 있습니다.
- Google에도 Bard가 있기 때문에 큰 영향이 없을 수 있을 것 같습니다.
- 시각적인 디자인과 이미지 검색, 지도 서비스 등을 강점으로 내세우며, 일부 국가에서는 Google 대신 주로 사용됩니다.
6. Yahoo

- 전 세계적으로 사용되는 검색 엔진 중 하나로, 다양한 국가에서 서비스를 제공합니다.
- 한 때는 한국에서도 많이 썼었습니다.
- 2012년 12월 31일에 한국에서는 철수하였습니다.
- 초기 무료 이메일 서비스로 소구하였으나, 모두 무료가 되어 의미 없어졌습니다.
- 뉴스, 스포츠, 금융 등의 컨텐츠와 검색 서비스를 통합하여 다양한 정보를 제공합니다.
'Marketing' 카테고리의 다른 글
| [SEO] 워드프레스 카테고리, 태그 없이 페이지로 메뉴, 목록 처리해도 될까? (1) | 2023.06.23 |
|---|---|
| 마케팅에서 심리학이 필요한 이유 10가지 (0) | 2023.06.14 |
| 퍼포먼스 마케터와 AE 차이는? | 퍼포먼스 마케터가 하는 일(직무), 전망, 연봉 (1) | 2023.05.24 |
| [광고심리학] 마케터라면 알아야할 인지심리학 주요 이론(개념) TOP 5 (0) | 2023.05.21 |
| [SNS란?]SNS에 대한 다양한 정의- 학술적 정의, 일반적 정의 (1) | 2023.05.18 |




댓글